")
Pokud například ze Screaming Frogu vyexportujete pouze URL obrázků a budete chtít po adminovi, ať je optimalizuje, nebude vás mít rád. Jedna věc je vědět, jakou má obrázek URL, druhá věc je vědět, na které URL adrese se nachází.
Screaming Frog vám dokáže přes bulk export sice vytáhnout, kde se obrázek nachází, ale i když to uděláte, bude vám stejně chybět celá řada informací. Nebo mě aspoň chyběla, proto jsem si vytvořil skript v Pythonu, který z webu vytáhne:
- všechny obrázky a URL kde se nachází
- jejich velikost v KB
- pokud je velikost v KB větší než 100 KB, přidá příznak „Příliš velké“, podle kterého lze filtrovat (Nejde o oficiální hodnotu Googlu, ale můj filtr. V článku níže najdete jak si nastavit velikost podle sebe)
- zjistí formát obrázku – to se hodí, pokud například hledáte jestli vám na webu nezůstaly nějaké .png apod.
- zkusí ověřit, jestli se používá CDN k posílání obrázku (určitě nedokáže detekovat všechny, snažil jsem se ale obsáhnout ty, na které narážím nejčastěji)
- ověří, jestli se obrázek načítá pomocí lazy-loading. Při identifikaci je závislý na IMG tagu loading == lazy.
- k obrázku vytáhne alt text, pokud tam nějaký je
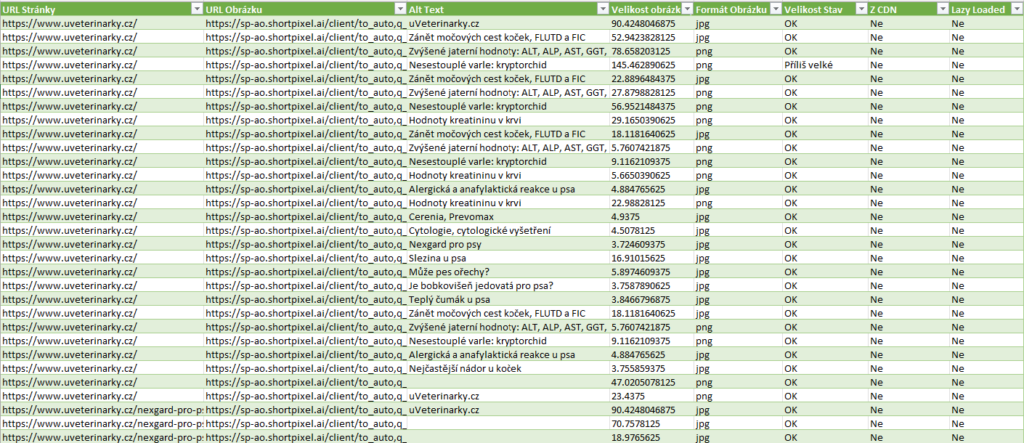
Stačí skript spustit a myslím si, že v tu chvíli máte jako SEO konzultant všechny informace, které pro optimalizaci obrázků potřebujete na jednom místě. Mě to šetří hromadu práce a na několik kliknutí vím, jak na tom obrázky na webu jsou.
Skript je určený primárně pro menší – střední weby. Není to nejefektivnější a pro velké eshopy se to nehodí. Pro ty mám rozdělaný crawler ve Scrapy, který bude procházet web daleko efektivněji. Jakmile ho budu mít, aktualizuji tento článek a dám zase k dispozici.
Upozornění: ⛔ I když jsem nikdy neměl problém s tím, že by to nějak nepřiměřeně vytěžovalo web, používejte to pouze pro weby, které optimalizujete. Je to něco, co vám má ušetřit práci a ne scrapovat konkurenci! Na to jsou tu profi nástroje.
Instalace požadovaných nástrojů
Pro využití tohoto Python skriptu je nezbytné mít nainstalované správné nástroje a knihovny. Tato část vás provede krok za krokem procesem instalace Pythonu, Visual Studio Code (volitelné) a potřebných Python knihoven.
Krok 1: Instalace Pythonu
- Navštivte oficiální stránku Pythonu: Přejděte na python.org a najděte sekci ke stažení (Downloads) pro váš operační systém (Windows, macOS, Linux/UNIX).
- Stáhněte Instalátor: Vyberte nejnovější verzi Pythonu ke stažení. Pro Windows uživatele, je doporučeno stáhnout buď 32-bit nebo 64-bit verzi podle specifikace vašeho systému.
- Spusťte instalátor: Otevřete stáhnutý soubor a nainstalujte. Důležité je zaškrtnout možnost „Add Python to PATH“ před spuštěním instalace, což umožní snadné spouštění Pythonu z příkazové řádky.
- Ověřte instalaci: Po dokončení instalace otevřete příkazovou řádku (CMD nebo Terminal) a zadejte
python --version.Pokud je Python správně nainstalován, měli byste vidět verzi Pythonu.
Volitelné: Krok 2: Instalace Visual Studio Code (VSCode)
Já preferuji VSCode, je to zdarma a zpřehledňuje to práci. Obejdete se ale bez toho. Vystačíte si s Poznámkovým blogem nebo Notepadem.
Pokud chcete používat VSCode:
- Navštivte Oficiální Stránku VSCode: Přejděte na code.visualstudio.com a stáhněte VSCode pro váš operační systém.
- Spusťte Instalátor VSCode: Po stažení spusťte instalátor a postupujte podle instrukcí na obrazovce. VSCode nevyžaduje žádné speciální nastavení během instalace.
- Ověřte Instalaci: Po instalaci otevřete VSCode, abyste se ujistili, že byl nainstalován správně.
Krok 3: Instalace potřebných knihoven Pythonu
- Otevřete Terminál nebo Příkazový řádek
- Instalace Knihoven: Použijte následující příkazy k instalaci knihoven potřebných pro skript:
pip install requestspip install beautifulsoup4pip install pandas- Tyto příkazy stáhnou a nainstalují knihovny requests pro práci s HTTP požadavky, BeautifulSoup pro parsování HTML a pandas pro manipulaci s daty.
Krok 4: Ověření instalace knihoven
- Po instalaci knihoven můžete jejich přítomnost ověřit spuštěním
pip listv Terminálu, což zobrazí seznam všech nainstalovaných Python balíčků.
Nyní jste připraveni na editaci a spuštění skriptu.
Spuštění skriptu
Nejprve si stáhněte skript. Doporučuji ho nechat ve složce, ve které se vám rozbalí. Složku doporučuji, protože v ní budeme skript spouštět a bude se vám do ní automaticky ukládat výstup v csv, tak abyste to nemuseli hledat potom po všech čertech.
Nejprve bude potřeba si skript upravit, aby scrapoval váš web (nebo web, který se chystáte scrapovat a máte s ním domluveno, že je to ok 😉 )
Skript si otevřete ve VSCode nebo Poznámkovém blogu/Notepadu a najděte řádek 47:
base_url = 'https://example.com' # Nahraďte 'https://example.com' skutečným URL
https://example.com nahraďte URL adresou webu, který chcete scrapovat. Nezapomeňte uložit (Soubor > Uložit)
Alternativně pro to můžete ve Windows použít Poznámkový blog nebo Notepad. Pro MAC můžete otevřít a editovat v TextEdit, v Linuxu Gedit nebo KWrite. Je to jedno v čem budete soubor editovat. Já mám rád VSCode protože na první dobrou vidíte čísla řádků a jestli někde nedošlo k chybě v syntaxi.
Až budete nahrazovat example.com vaším webem, dejte si pozor, ať zadáváte celou URL adresu včetně hhtp nebo https. Důležité také je, aby adresa webu byla uvnitř původních uvozovek.
Můžete si také upravit velikost obrázku v KB, u které se vám má vrátit, že je obrázek příliš velký. Hodnota 100 KB, která je tam nastavená je hodnota, kterou většinou používám já, ale nejde o žádné oficiální číslo od Googlu. Google žádnou konkrétní hodnotu neuvádí, takže je na vašem uvážení, co považujete za limitní velikost obrázků, u které se chcete podívat, jak rychle se stránka načítá.
Hodnotu si upravíte na řádku 79:
size_status = "Příliš velké" if img_size_kb > 100 else "OK"
Hodnotu 100 změňte za vaši požadovanou velikost a nezapomeňte uložit.
Ve složce, kde máte uložený skript scrapovani_obrazku.py si otevřete Terminál (pravé tlačíko myši).
V terminálu zadejte:
python scrape_obrazku.pyPoté by se skript měl rozeběhnout a vy byste měli vidět tuto obrazovku. Skript poběží dlouho podle toho, jak je velký web, který scrapujete.
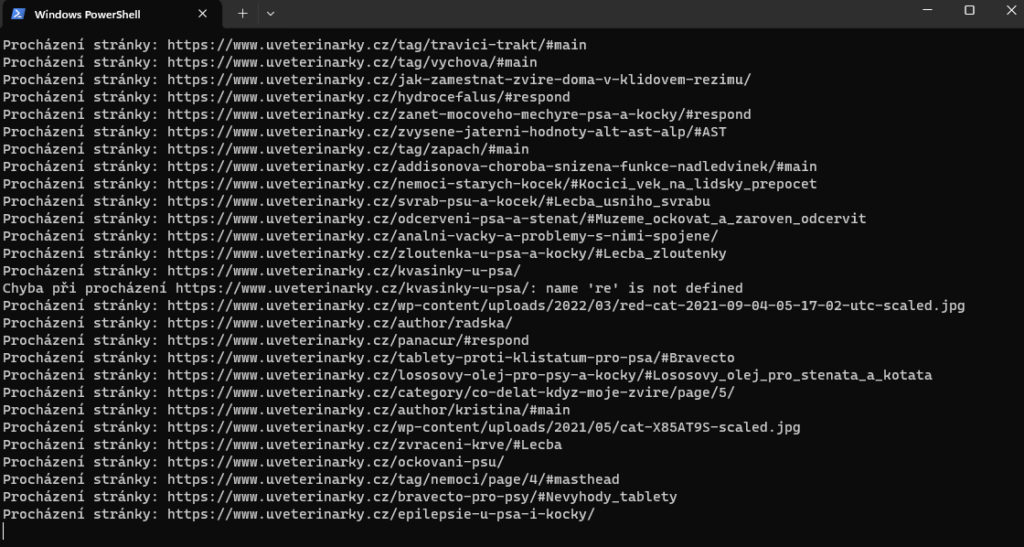
Hotový výstup
Poté co skript doběhne, uvidíte v konzoli info:
Scrapování dokončeno. Data uložena do 'vyscrapovane_obrazky.csv'
Vaše vyscrapované obrázky máte nyní uložené ve složce, kde máte uložený skript, jako vyscrapovane_obrazky.csv
Abyste s dokumentem mohli dále pracovat, je potřeba si ho načíst do Excelu jako datový zdroj a pak už můžete s daty pracovat jak potřebujete. Kdo by nevěděl, jak na CSV soubory, zde je hezký návod.